Org-mode is my exocortex, second brain, second mind, mind palace, pensive, personal knowledge management system, and apocrypha. It’s very flexible and the features I use as well as how I organize my files continues to change so I collected things here to document how I do things in 2024, I did this in 2023 as well1.
No, my Emacs org-mode configuration is not published. However, if you have some question, just reach out.

Goal
Unrealistically or not, I want total recall, to remember everything in durable plain text. I want to have control of my data. I want to do my work and interact efficiently. I want to improve my knowledge and capabilities, and I want to be able to share with others.
On the best of days I never leave Emacs and I have a record of everything I did as well as how much time I spent on each thing.

Statistics
As of Monday, June 3, 2024
I had 62MB of .org files in ~/org. 5441 files and 1289699 lines of text, the largest single file was 1.4MB and the longest lined file had 26370 lines.
5412 of these files were inside Org-roam2, the majority of them (3940) were “dailies”3. There were 16670 nodes in total, so about 3 nodes per file. This seemed accurate since many headlines (I had 58212 headlines) didn’t have IDs. IDs got created automatically when I stored a link (which often happened during capture) or attached a file.
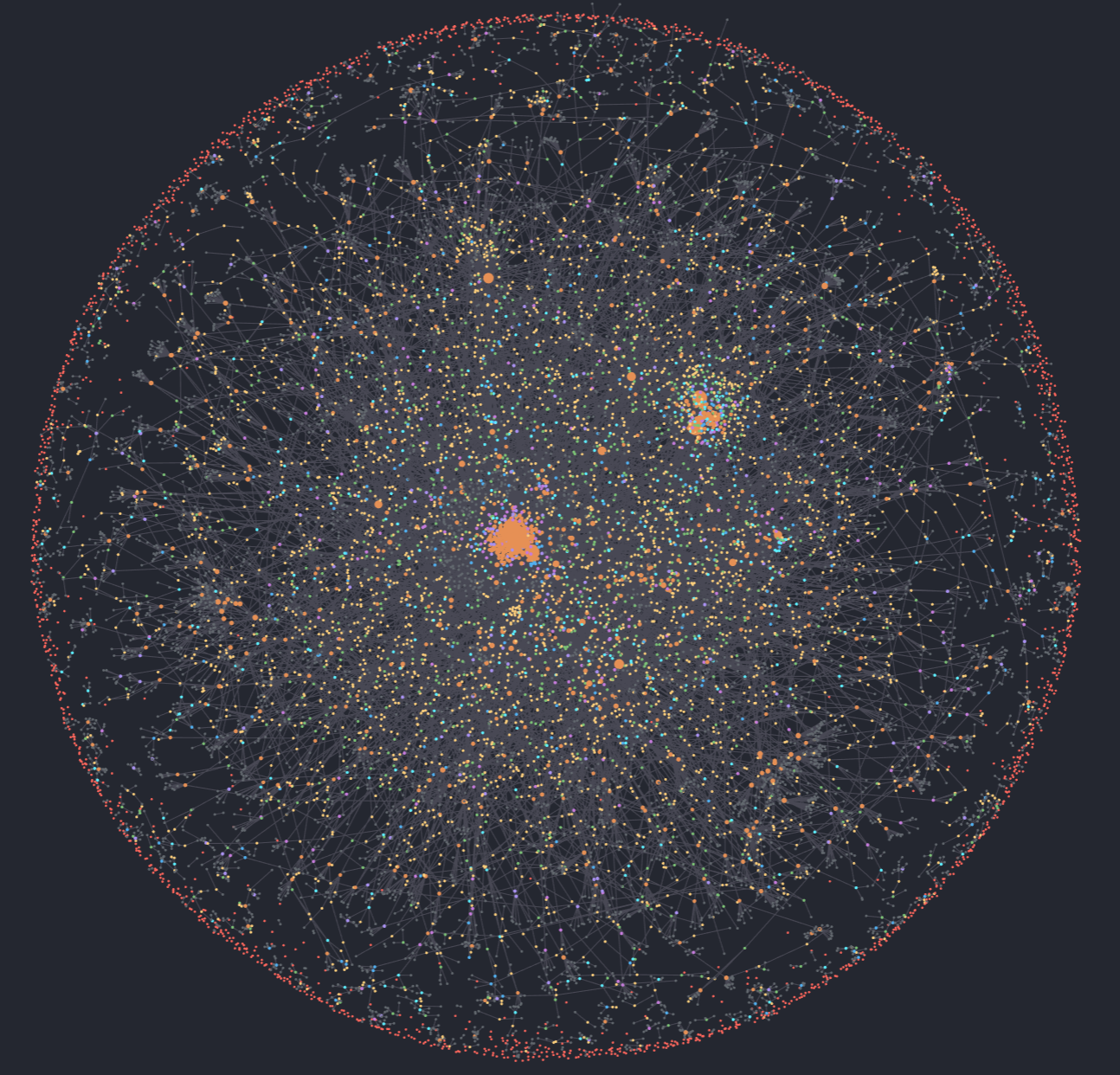
Figure 1: org-roam-ui visualization of nodes as of January 16th, 2024.
SSS
System
There was no real formal system in use here. Pretty much the Nick Anderson S.H.I.T. (Stuff here ’n there) methodology.
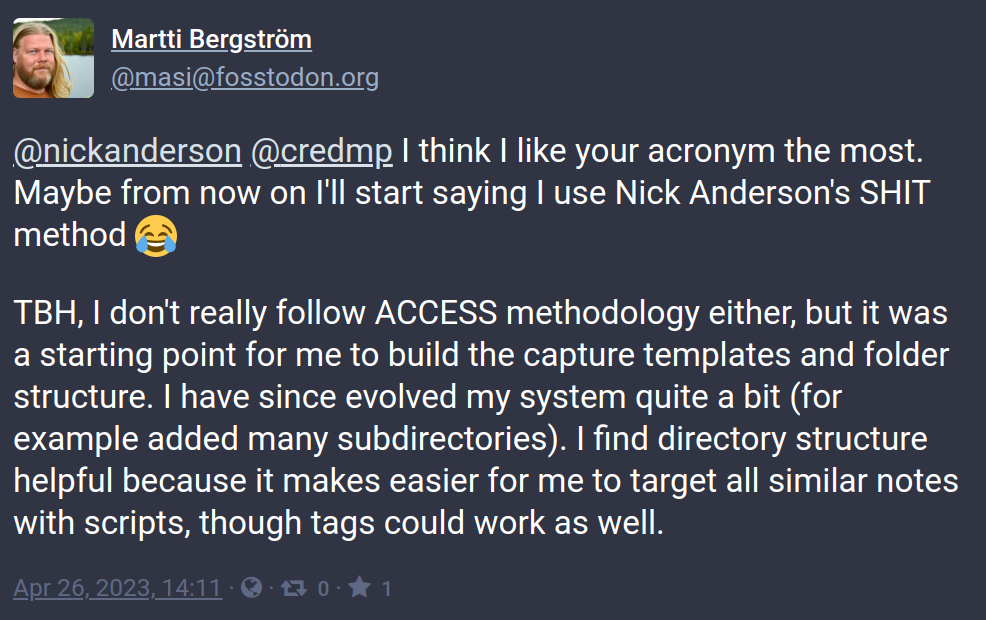
Figure 2: Martti Bergström (@masi@fosstodon.org) uses the Nick Anderson SHIT meethod. https://fosstodon.org/@masi/110266696809445948
I appreciated reading about various workflows and methodologies like PARA, CODE, ACCESS, Johnny Decimal, etc … but I liked to do what works for me, and that has been an ever-changing target. I would say that my process was perhaps most closely aligned with CODE (Capture, Organize, Distill, Express).
Capture
Capturing was an important concept in my workflow. Fundamentally it’s grabbing new content and putting it somewhere. It facilitated consistency and automated some tedium of organization. I needed capturing to be fast and not interrupt my flow.
Org-roam was my primary capture interface and I really liked the daily capabilities. Each day I captured notes about everything I was working on into my work log while clocking time. This gave me a nice place to think and process what I was working on4 as well as a place to get my bearings and see what I had been working on when I got side-tracked5. Having a new file each day gave me a fresh start and it helped me to avoid performance issues I had previously experienced with large (multi-megabyte) files.
I had 24 org-capture-templates, 19 org-roam-capture-templates and 78 org-roam-dailies-capture-templates.
Capture templates helped me
-
Remember relationships between notes. Many included
%a6 to create a link to the node where I was when the capture was initiated with my configuration automatically creating an ID in the source node if necessary. I preferred ID links as they don’t break as I move files around. -
Automatically organize captured content. I capture to my work log the most, but as I identify recurring similar content I create templates to ensure like content is stored together.
-
Track time spent. Only my work log capture template clocks time. Work log entries might contain the details of the work I was doing, or if it’s related to work being done over multiple days might link to another node where those details are stored. If I am working on a specific project where time tracking is needed I will manually clock time in the project related files. At times I feel a desire for concurrent clocking but I hadn’t made any efforts to see how to implement such capability. Org-mode already provided capabilities to help avoid clocking multiple things concurrently and I hadn’t convinced myself that concurrent clocking was really needed.
-
Initialize new files. Org-mode can create new files and the outline path to the captured node, but alone it has no capability to initialize content outside the capture target. Org-roam’s capture templates have the ability to initialize the reset of the file if target file does not already exist.
-
Setup nodes for export. For many of my recurring meetings I like to send out my notes to my team. My capture templates initialize the mail related properties so that I can easily export and sent my note via email.
Other tools used for capture
Some of the features that I used to get content into Org-mode were not part of org-capture.
I used org-rich-yank7 often, which let me copy text and paste it with context allowing it to be syntax highlighted as well as providing a link back to the source.
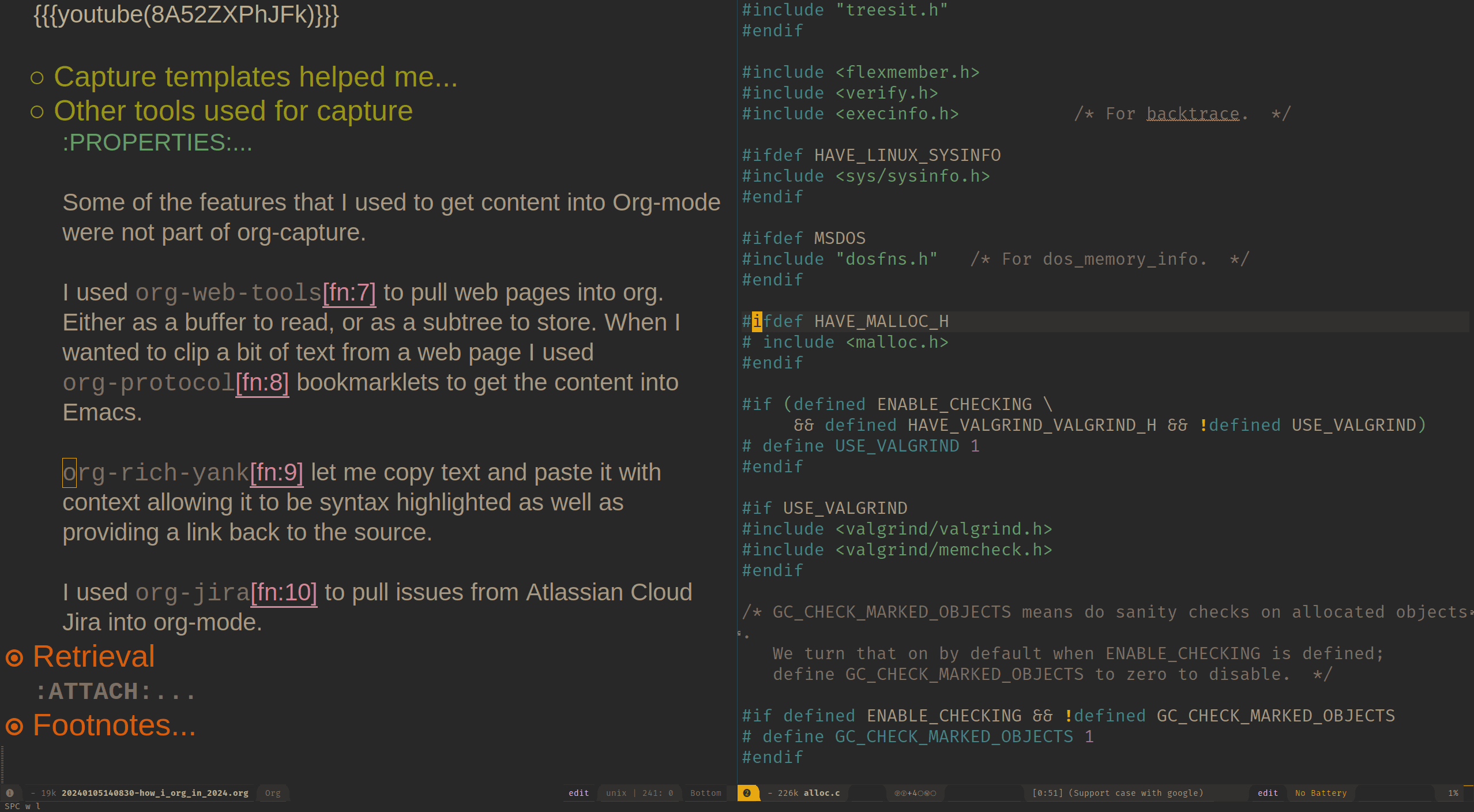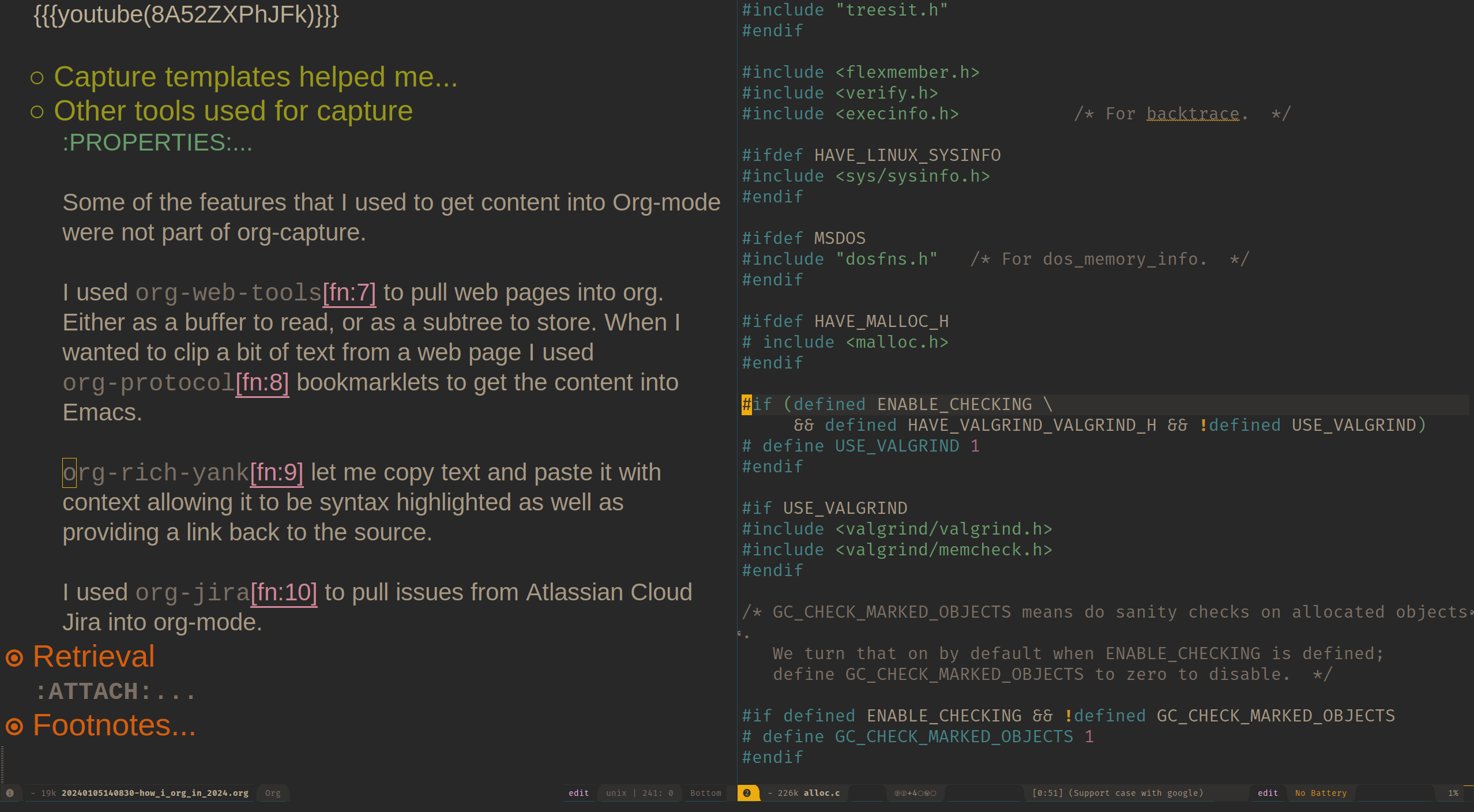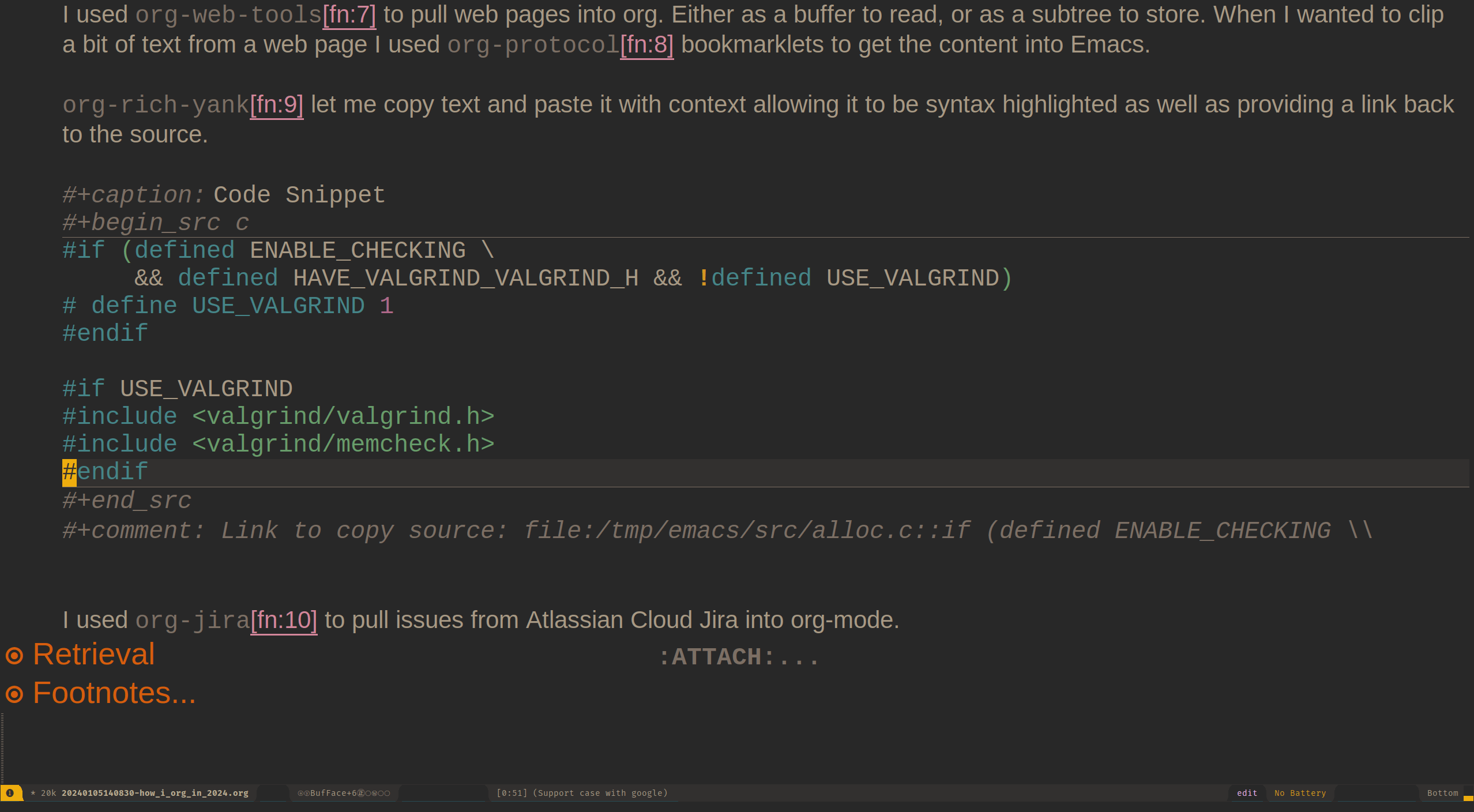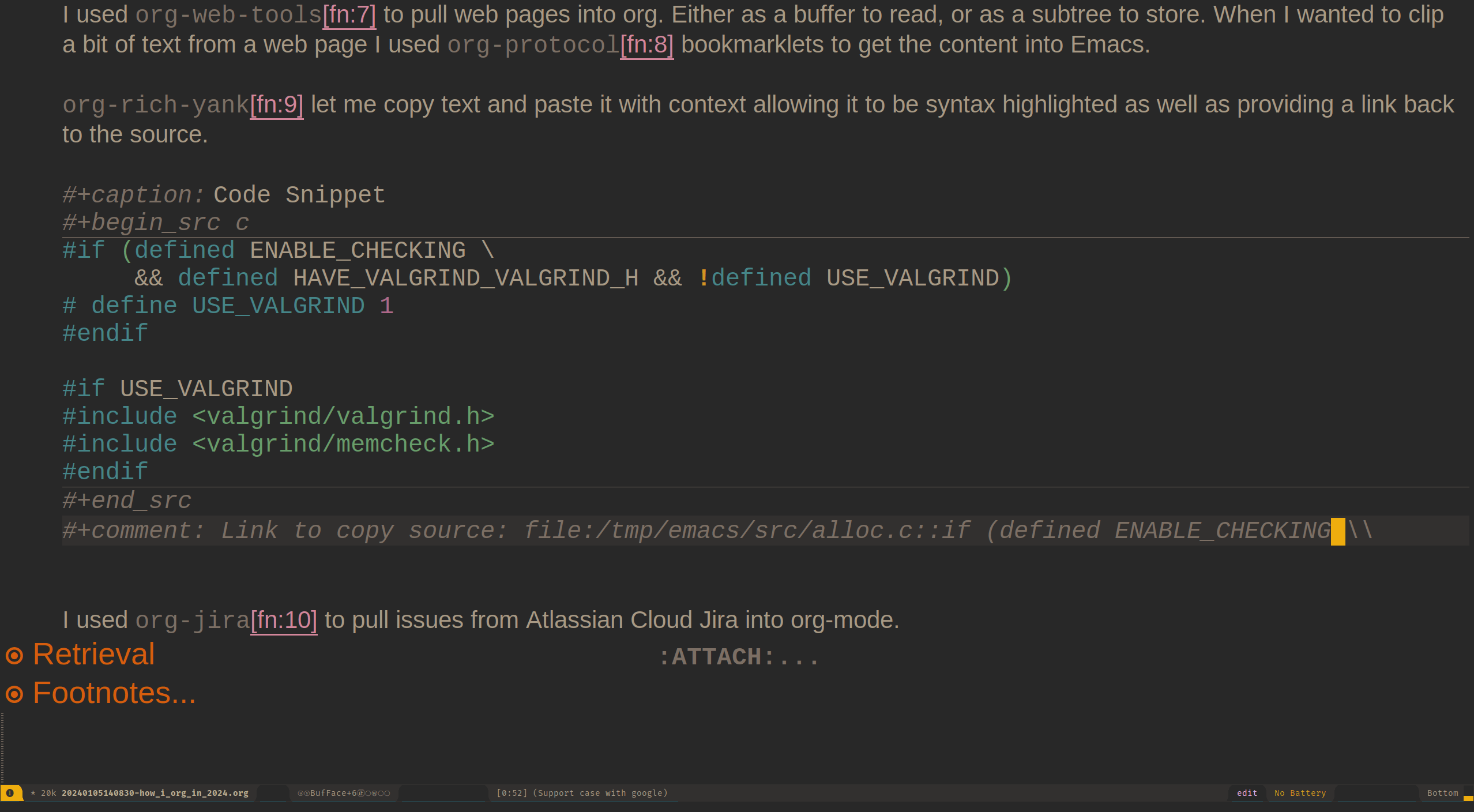
Figure 3: gif-screencast illustrating use of org-rich-yank.
I read email in mu4e, simply being inside of Emacs that facilitate getting emails into org-mode.
I occasionally used org-web-tools8 to pull web pages into org. Either as a buffer to read, or as a subtree to store.
Figure 4: gif-screencast illustrating use of org-web-tools-read-as-org.
When I wanted to clip a bit of text from a web page I used org-protocol9 bookmarklets to get the content into Emacs.
I used org-jira10 to pull issues from Atlassian Cloud Jira into org-mode.
I used gif-screencast 11 to record many of the animations found on this page.
I used org-download 12to facilitate dragging things onto my buffer to attach them and downloading files (usually images) as attachments. It provided a screenshot tool but I didn’t tend to use it.
I occasionally used some elisp from sachachua’s 13blog to download youtube videos with their transcripts.
I had some memacs jobs running, but no plan for using the data. It felt like getting comfortable with agenda was perhaps a pre-requisite for value.
Retrieval
I retrieved content from my org in a myriad of ways.
I used org-roam-goto-today usually keying in wll (work log log) frequently to get back to home base.
Often I would find notes by name using org-roam-node-find. This worked well for finding notes with a regular naming pattern, e.g. I took notes on the work I did while releasing new software versions. The capture template for that type of note created files titled Release work for X, so it was quick and easy to org-roam-node-find, type Release work for 3.18.7, and jump to that note. Similarly, I kept notes on individual people, those notes were titled with the persons name, so it was quick to org-roam-node-find and start typing the persons name to find their note.
I frequently found notes via link. org-roam-node-insert made it easy to simply insert a link to another note (found by name as noted above) which I could then jump follow. Many of my capture templates also contain links, some to well known related notes and some using %a 6 to provide a link to the location I was when I decided to initiate the capture. So, when I wanted to find the notes for the ticket I was working on the day prior I would visit the worklog for the day and find the headline where I was clocking time related to the ticket and follow the link to the ticket notes. That annotation link (%a) can result in links to unrelated things, but I had found the ability to track back and be aware of unrelated things that were happening around that time to be useful during some archaeology sessions.
Sometimes I would use org-roam-buffer to get a view on which notes link to my current note.
Searching by name is not always effective, sometimes I needed to search widely and dive deep searching for specific strings. For that, most often I used org-ripgrep-consult.
For serendipitous stumbles, I occasionally used org-roam-random-note to surface some random note.
I long desired to make effective use of org-agenda and I had played around with using org-roam-db-query to identify which files contained TODO keywords to keep the files loaded by org-agenda to a minimum, but I had yet to really make agenda part of my routine. I also tried using org-idle-agenda to keep bringing it front and center but I struggled to get comfortable.
I revisited org-ql in early February and found a patch that enabled specifying multiple files to use as source for the query. I combined this with a poorly written elisp function that returns the last 3 months worth of worklog files (the same function that I use for clocktables). This felt like a less ephermal agenda. I liked the pain textness of it, how I wouldn’t need emacs to view yesterdays agenda simply by looking at yesterdays worklog. So it quickly became part of my daily workflow. I added an org-ql dynamic block to my daily worklog template giving me a quick idea of things I should focus on. It did really highlight the cases where I end up with multiple todos for the same item across multiple files so I needed to figure out how I wanted to improve that. I was considering canceling todos from prior days when I chose to pick it up in a new todo, or moving the heading forward, or adding a new todo state for carried over, or expanding the scope of the query to look in other places but knowing where to look is tricky, but I wasn’t sure if I even needed to worry about volume of files, it’s not agenda after all.
org-roam-dynamic-blocks 14 stayed on my radar, but I had yet to really make it an active part of my workflow.
Output
Output was a very important aspect of my system. It was important to me to be able to easily share my knowledge and experience with others.
I used org-babel frequently. It was very convenient and efficient to be able to execute code directly in my documents.
Copying and pasting between a console and what I was writing introduced much chance for error. Having code blocks and in-line execution improve the accuracy of my notes and anything else that I was producing.
For example, the Statistics section of this post used inline code blocks and the data was freshly generated each time I exported an updated version with ox-hugo. Named blocks let me inject dynamic content in a sentence and provided easy access for on-demand execution, not to mention the ability to leveraged as input for other blocks.
For some time I had struggled with long running jobs blocking Emacs. I had used ob-async in the past in the prior few years seemed to run into issues with ob-async not working. I also wanted something that would work better for very long running jobs (like 7+ hours). In February I experimented with ob-tmux which was neat, but then I was seeing tmux crash and ended up having better success with ob-screen.
I continued to make more consistent use of org-transclusion15 while authoring content. Instead of duplicating content, copying to a new place I distilled what I want to use into an atomic chunk and then referenced it. I found this is helpful in several ways. It reduced unnecessary growth to the volume of text that I had, reduced the number of duplicate hits for things when I was searching for something, increased the interlinking of my org-mode files providing a more rich experience with org-roam-buffer showing things that used the content as well as interconnected in the org-roam-ui graph visualization.
With so many export backends available I didn’t usually have to spend time mucking around with some bespoke syntax. I could author in org-mode and quickly export it to another format. It was nice to have relatively good formatting in many formats with relatively little effort.
I exported using ox-jira and used org-jira to manage issues in Jira Cloud. Again, everyone benefited from well styled comments and ticket descriptions and no real extra effort was required from me.
I made presentations using org-reveal and org-re-reveal with nice features like speaker notes. These presentations could also be printed to PDF. I played with org-present and org-tree-slide but not enough to gain a good level of comfort.
I wrote reports that I exported to ODT for copying and pasting into google drive16 and PDF for emailing to clients.
I wrote blog posts exporting with ox-hugo to multiple websites using different hugo configurations.
I authored emails in org-mode exported with org-mime17 as a multi-part ASCII & HTML message.
abbrev-mode was amazing at auto correcting my most common typos. writegood-mode and olivette were both nice for writing when I remembered to enable them.
gptel was my primary llm interface. I interfaced primarily with local LLMs via Ollama but had Google Gemini and OpenAI configured for use as well. I looked forward to support for image generation (though there was no indication it was coming). I also used chatgpt-shell, org-ai, and ellama from time to time. Sadly Khoj fell by the wayside as I had many issues keeping it functional with their rapid development and architecture changes but I remained hopeful that I would return to it in the future.
Workflow
So, how did a day in my org life flow?
Usually my day started with meetings. I liked to take notes and email them to a distribution list afterward18. For example, a few minutes before my CFEngine stand-up I ran org-roam-dailies-capture-today and keyed in w (work) m (meeting) c (CFEngine) d (daily stand-up). Immediately after activating this capture I triggered another capture for my work log keying in w (work) l (log)19 which clocked time. With so many templates I used mnemonic key bindings.
The work log capture template included a link to the stand-up note for the day. I followed that link and started filling out my template. The template featured a headline for each person with a property linking to a node for the individual. My section contained a clock table that promptly generated a list of entries with clocked time from the preceding day (on Mondays or days when I had missed several prior days, I adjusted the clock table to retrieve the appropriate number of previous days). I examined the table to assess my performance in clocking the previous day and filled in any gaps that I had neglected to record, then deleted the time columns.
At the end of the meeting, I used org-mime17 to prepare a nicely formatted multipart ASCII & HTML email. After sending the mail, I switched back to my work log capture and completed it. All of my regularly scheduled meetings followed the same process; I captured for the meeting template, then I captured to my work log, clocking time with an automatic backlink back to the specific meeting note. It was easy to capture notes for yesterday, tomorrow, or an arbitrary date in the future using org-roam-dailies-capture-yesterday, org-roam-dailies-capture-tomorrow, and org-roam-dailies-capture-date.
When initializing a new daily worklog file the template also included an org-ql dynamic block showing TODO, WAITING, and INPROGRESS tasks from the prior 3 months helping to surface things I had been working on (or intended to work on ) recently that needed follow-up. I liked the less ephermal nature of the dynamic block in comparison to agenda which I continued to struggle getting comfortable with.
Org-roam provided useful functions for accessing time-series notes. org-roam-dailies-goto-today took users to today’s note for the selected template. If the file did not exist, it was initialized. Similarly, org-roam-dailies-goto-yesterday, org-roam-dailies-goto-tomorrow, and org-roam-dailies-goto-date took users to the note for yesterday, tomorrow, or the specified date and created the file if necessary. org-roam-dailies-goto-previous and org-roam-dailies-goto-next navigated to the previous and next note in the series based on the file being visited, enabling easy navigation through the time series.
org-roam-node-random was fun, as it says, it takes you to a random node. It was nice for serendipitous stumbles but I barely ever used it.
If I worked on something with a regular pattern but it was not a recurring time series, I followed a similar pattern. However, instead of org-roam-dailies-capture, I ran org-roam-capture. Unlike org-roam-dailies-capture, org-roam-capture prompted me first for a node title and then allowed me to select a template.
For instance, if I worked on a support case, I would run org-roam-capture, enter the issue number, and then key in w (work) s (support). I was taken to a new node in the file for that support case where I immediately triggered org-roam-dailies-capture for my work log which started clocking time. I followed the link back to the node to continue my work.
For other activities that were typically fast or of uncommon type spanning multiple days, I would run org-roam-dailies-capture and keep notes directly in my past work log.
I authored much of the content in org-mode. I was often able to remain within org-mode and preserved a detailed record of my exact activities. When I needed to execute commands, I typically employed org-babel so that commands, their outputs, and my contemplations formed a substantial log of my work as it progressed. This log was frequently appropriate for direct transmission to others, for which purpose I capitalized on the ample export back ends available20.
Mobile
Going mobile with org mode, I used several different applications:
I utilized Syncthing to synchronize files across devices, syncing a subset of my org files to mobile devices. I didn’t require access to my entire exocortex on the go.
Orgzly served as my primary capture tool on mobile. My Orgzly directory was synchronized across all my mobile devices. Each device had a device-specific file configured as the Default notebook.
I enjoyed the home screen widget, which displayed a query showing notes from the device-specific file created in the last few days. For note-taking, I used the + button on the home screen widget. There was also a new note option in the notifications drop-down drawer, but I generally refrained from using it.
It was serviceable for short notes, such as Saw Brian at the store; he broke his foot. We should get together and grill, or lists for the store, e.g., TODO Milk :store, TODO Black Beans :store.
It simplified managing trips to the store. However, the editing experience was lacking, and I longed for improved capture capabilities. It handled deep directory structures, which wasn’t an issue for me but would have been a valuable feature. I missed having this functionality.
I had not encountered sync conflicts since I introduced a Tasker automation to synchronize the Orgzly database on screen wake21 and adopted the practice of having one capture file per mobile device.
I filed my Orgzly captures to my main system far less often than I should. They were typically transferred to my personal journal. I hoped to eventually implement a function to refile them to a specific org-roam-dailies capture template for the date under point or maybe earliest or latest timestamp.22
Other applications that I used on mobile that deserve mention:
- Logseq
- I really liked how daily files are featured. I missed a capture capability. I disliked how the share to target is not stable. It shared to the insertion point. So if the app was open in the background that share might have gone to some random place I stopped writing. It was convenient at times, but other times very inconvenient. I didn’t love the editing interface. Everything was a headline, so it’s a bit ugly when I come to the file in Emacs. I mostly used it in experiments to help a colleague get more from their use. Unfortunately, it seems they are shifting to a db first model so it’s futures alignment with my priorities were in question.
- Metanote
- I didn’t see other people mention this one often. I had found it to be a bit slow but the editing UI was not bad. Also, it had a few capture templates as well as Agenda.
- Orgro
- No longer a read only tool, but I haven’t tried it’s edit capabilities.
Things I used frequently
I use these packages quite often and they are pretty well established in my workflow.
org-roam
org-mime
org-rich-yank
org-transclusion
gptel
org-ql
This package provides a query language for Org files. It offers two syntax styles: Lisp-like sexps and search engine-like keywords. I’d started using the dynamic block feature of this with a custom patch to have a table of TODOs at the top of my daily worklog.
https://github.com/alphapapa/org-ql
ox-hugo
ox-slack
org-jira
Things I wanted to explore more
I had only recently begun to think about myself as being an Emacs user, I have felt like an org-mode user but with my need for vi keybindings, Emacs really didn’t rise to the forefront of my mind. Here are a bunch of things that I wanted to explore further as I continued on my journey.
ob-translate
Translate text in Emacs’ org-mode blocks.
https://github.com/krisajenkins/ob-translate
md4rd
Read Reddit interactively from within Emacs.
https://github.com/ahungry/md4rd
Ement.el
Ement.el is a Matrix client for Emacs. It aims to be simple, fast, featureful, and reliable.
https://github.com/alphapapa/ement.el
elfeed
Elfeed is an extensible web feed reader for Emacs, supporting both Atom and RSS.
https://github.com/skeeto/elfeed
mastadon.el
Emacs client for Mastodon and other compatible fediverse servers.
https://codeberg.org/martianh/mastodon.el
org-chef
org-chef is a package for managing recipes in org-mode. One of the main features is that it can automatically extract recipes from websites like allrecipes.com
https://github.com/Chobbes/org-chef
org-drill
Org-Drill is an extension for Org mode. Org-Drill uses a spaced repetition algorithm to conduct interactive “drill sessions”, using org files as sources of facts to be memorised. Each topic is treated as a “flash card”.
https://orgmode.org/worg/org-contrib/org-drill.html
org-roam-search
org-ql like search for org-roam.
https://github.com/natask/org-roam-search
org-edna
Extensible Dependencies ’N’ Actions (EDNA) for Org Mode tasks. Edna provides an extensible means of specifying conditions which must be fulfilled before a task can be completed and actions to take once it is.
https://www.nongnu.org/org-edna-el/
org-mru-clock
Do you often clock in to many different little tasks? Are you annoyed that you can’t just clock in to one of your most recent tasks after restarting Emacs?
https://github.com/unhammer/org-mru-clock.
org-noter
Org-noter’s purpose is to let you create notes that are kept in sync when you scroll through the document, but that are external to it - the notes themselves live in an Org-mode file.
https://github.com/weirdNox/org-noter
org-cv
This project exports an org-mode file with reasonably structured items into a latex file, which compiles into a nice CV. I’d been at Northern.tech for > 10 years with little reason to update any kind of CV, but you never know what the future might bring.
https://titan-c.gitlab.io/org-cv/
ox-leanpub
Ox-leanpub includes Org Mode export backends to publish books and courses with Leanpub. ox-leanpub allows you to write your material entirely in Org mode, and manages the production of the files and directories needed for Leanpub to render your book.
https://github.com/zzamboni/ox-leanpub
org-super-agenda
This package lets you “supercharge” your Org daily/weekly agenda. The idea is to group items into sections, rather than having them all in one big list.
https://github.com/alphapapa/org-super-agenda
org-recent-headings
This package lets you quickly jump to recently used Org headings using Helm, Ivy, or plain-ol’ completing-read.
https://github.com/alphapapa/org-recent-headings
org-sidebar
This package presents helpful sidebars for Org buffers. Sidebars are customizable using org-ql queries and org-super-agenda grouping.
https://github.com/alphapapa/org-sidebar
org-protocol-capture-html
You can select text in the page when you capture by clicking a bookmarklet it will be copied into the template, or you can just capture the page title and URL. A selection-grabbing function is used to capture the selection.
https://github.com/alphapapa/org-protocol-capture-html
emacs-slack
Slack from inside Emacs. Well, I used slack at work, primarily via the electron app. But, things being inside emacs facilitate an easy flow of information between other places and my org-mode apocrypha.
https://github.com/yuya373/emacs-slack/
literate-calc-mode
Literate programming for M-x calc. Displays inline results for calculations, supports variables and updates as you type (if you want).
https://github.com/sulami/literate-calc-mode.el
org-similarity
org-similarity is a package to help Emacs org-mode users discover similar or related files. Under the hood, it uses Python and scikit-learn for text feature extraction, and nltk for text pre-processing. More specifically, this package provides a function to recursively scan a given directory for org files, clean their content by stripping the front matter and some undesired characters, tokenize them, replace each token with its respective linguistic stem, generate a TF-IDF sparse matrix, and calculate the cosine similarity between these documents and the buffer you are currently working on.
https://github.com/brunoarine/org-similarity
focused
A package that dims surrounding text. It works with any theme and can be configured to focus in on different regions like sentences, paragraphs or code-blocks.
https://github.com/larstvei/Focus
aggressive-indent-mode
A minor mode that keeps your code always indented. It re-indents after every change, making it more reliable than electric-indent-mode.
https://github.com/Malabarba/aggressive-indent-mode
crux
A Collection of Ridiculously Useful eXtensions for Emacs. crux bundles many useful interactive commands to enhance your overall Emacs experience.
https://github.com/bbatsov/crux
osm
Osm.el is a tile-based map viewer, with a responsive movable and zoomable display. You can bookmark your favorite locations using regular Emacs bookmarks or create links from Org files to locations.
org-ref
org-ref makes it easy to insert citations, cross-references, indexes and glossaries as hyper-functional links into org files.
https://github.com/jkitchin/org-ref
org-cite
I haven’t really used citations, but it seems like I could really benefit from it some day.
https://orgmode.org/manual/Citations.html
org-bibtex
Org-bibtex is responsible for handling bibtex citation in orgmode.
http://gewhere.github.io/org-bibtex
orgmdb
Tools for managing your watchlist in org-mode and some functions for interacting with OMDb API.
https://github.com/isamert/orgmdb.el
org-roam-review
Provides commands to categorise and review org-roam nodes for Evergreen note-taking. Notes are surfaced using the spaced-repetition algorithm from org-drill.
https://github.com/chrisbarrett/nursery/blob/main/lisp/org-roam-review.el
org-pretty-table
Draw pretty unicode tables in org-mode and orgtbl-mode.
https://github.com/Fuco1/org-pretty-table
org-roam-timestamps
Small package to keep track of the modification and creation time of individual nodes.
https://github.com/tefkah/org-roam-timestamps
camcorder.el
Record screencasts directly from emacs. I used this occasionally to record screen casts but it had yet to rise to regular use.
https://github.com/Malabarba/camcorder.el
org-msg
Use org-mode for authoring email. Seems to be centered around mail client use vs org-mime which seems more around emailing from org-mode.
https://github.com/jeremy-compostella/org-msg
gptai
One of the many ai related things I want to look into some day.
https://github.com/antonhibl/gptai
chatgpt
One of the many ai related things I want to look into some day.
https://github.com/emacs-openai/chatgpt
codegpt
One of the many ai related things I want to look into some day.
https://github.com/emacs-openai/codegpt
ChatGPT.el
One of the many ai related things I want to look into some day.
https://github.com/joshcho/ChatGPT.el
gpt.el
One of the many ai related things I want to look into some day.
https://github.com/stuhlmueller/gpt.el
chatgpt-arcana.el
One of the many ai related things I want to look into some day.
https://github.com/CarlQLange/chatgpt-arcana.el
openai-api.el
One of the many ai related things I want to look into some day.
https://github.com/benjamin-asdf/openai-api.el
chatgpt emacs shell
One of the many ai related things I want to look into some day.
https://xenodium.com/a-chatgpt-emacs-shell/
pocket-reader.el
Client for Pocket (getpocket.com) that allows you to manage your reading list (add, remove, delete, tag, view, favorite, etc ..) within Emacs. I sometimes have gone through spurts of use of pocket, but not consistently. If I was to get into it, this is something I wanted to leverage.
gkroam
Another replica of roam research implemented using ripgrep. https://github.com/Kinneyzhang/gkroam
org-media-note
For taking notes on video and audio files in org-mode! Very cool for when I have this sort of desire, though it’s not a frequent occurrence.
https://github.com/yuchen-lea/org-media-note
dslide
In May I came across yet another text based presentation framework, dslide. It looks pretty nice, a direct descendant of org-tree-slide. I really like the idea of using text based slides, when doing trainings I often end up sharing an org-mode document while working through questions and examples, but I still gravitate toward a reveal.js exporter like org-reveal or org-re-reveal.
https://github.com/positron-solutions/dslide
org-node
I came across org-node by way of a post on Mastadon near the end of April. It’s an org-roam work-a-like, but avoids the database using rg and some custom caching. It’s id centric, which would be a good fit for me.
I played with it a bit and intend to keep trying it out but my current org-roam-node-find works well for me. It’s fast enough and faster than what I am getting from org-node so far. I don’t have any issue with org-roam using sqlite, but the thought of having similar basic functionality without need for that extra bit is one I like.
Things I came across that were interesting, but not for me
While these weren’t a good fit for me, they might be something you are interested in.
zettledeft
Extends Deft into a basic zettelkasten. As of 2023 the author has ceased maintenance and is moving to denote. https://github.com/localauthor/zk
denote
Simple note taking tool using predictable and descriptive file-naming scheme. It seemed like a great package, but it’s very file based and I felt like my workflow around IDs was better for me. Also felt like a lot of org-roam inertia to overcome to give it a serious try.
https://github.com/protesilaos/denote
orgrr
A replica of org-roam v1 implemented using ripgrep. It seems pretty fast, but it’s was quite file centric and I was pretty happy with my ID based workflow.
https://github.com/rtrppl/orgrr
zk
Another simple Zettlekasten implementation for Emacs.
https://github.com/localauthor/zk
-
How I org in 2023 https://cmdln.org/2023/03/25/how-i-org-in-2023/ ↩︎
-
Org-roam is a plain-text personal knowledge management system. According to the introduction in the manual Org-roam is a tool for networked thought. It reproduces some of Roam Research’s key features within Org-mode. Org-roam allows for effortless non-hierarchical note-taking: with Org-roam, notes flow naturally, making note-taking fun and easy. Really, it facilitates capturing information by extending Org-mode’s existing capture system, maintains a sqlite database of nodes (headings) with IDs and other metadata and provides the ability to surface and navigate back links (which nodes link to the current node). https://www.orgroam.com/ ↩︎
-
Org-roam dailies are files organized by date. I use them for my journal, work log, and recurring meetings. ↩︎
-
Maggie Appleton has a nice post about Daily notes as a frictionless default input for personal knowledge management systems. ↩︎
-
I am not perfect in remembering to capture each thing but I don’t need to be perfect to be effective. ↩︎
-
%a- Annotation, normally the link created withorg-store-link. ↩︎ ↩︎ -
org-rich-yankdoesn’t get enough publicity, I used it many times a day. It pastes the last copied text and automatically surrounds the snippet in blocks, marked with the major mode of where the code came from, and adds a link to the source file after the block. I recommend customizingorg-rich-yank-format-pasteand making the link to the source a comment as described in the README. https://github.com/unhammer/org-rich-yank ↩︎ -
org-web-toolscontains library functions and commands useful for retrieving web page content and processing it into Org-mode content. https://github.com/alphapapa/org-web-tools ↩︎ -
org-protocolintercepts calls from emacsclient to trigger custom actions without external dependencies. Only one protocol has to be configured with your external applications or the operating system, to trigger an arbitrary number of custom actions. https://orgmode.org/worg/org-contrib/org-protocol.html ↩︎ -
org-jirafacilitates getting content from Jira into org-mode and managing Jira issues from org-mode. https://github.com/ahungry/org-jira ↩︎ -
gif-screencastcaptures one frame per user action and let’s me stay inside Emacs while doing so. The project can be found here: https://gitlab.com/ambrevar/emacs-gif-screencast ↩︎ -
Find org-download here: https://github.com/abo-abo/org-download ↩︎
-
I edited the elisp to switch from
youtube-dltoyt-dlp. ↩︎ -
org-roam-dynamic-blocksis not yet packaged, but you can find it here https://github.com/chrisbarrett/nursery/blob/main/lisp/org-roam-dblocks.el. Perhaps someday it will become part of Org-roam https://github.com/org-roam/org-roam/issues/2251 ↩︎ -
Org-transclusion lets you insert a copy of text content via a file link or ID link within an Org file. It lets you have the same content present in different buffers at the same time without copy-and-pasting it. Edit the source of the content, and you can refresh the transcluded copies to the up-to-date state. https://github.com/nobiot/org-transclusion ↩︎
-
I wonder if html would work for a copy source pasting into a google doc as well or better. ↩︎
-
I’ve been told multiple times by colleagues that they search out my meeting notes to help themselves complete periodic reviews. I hate doing periodic reviews, so knowing that my effort helps others in this regard is a strong motivator. ↩︎
-
(maybe someone can suggest how that tho step process could be consolidated) ↩︎
-
There are so many, org-mime is probably my most often used exporter followed by some flavor of Markdown (ox-hugo like this blog post, ox-gfm, ox-slack). ↩︎
-
I have an
Orgzlyprofile with an event forDisplay Onthat triggers aSync Orgzlytask which is an Actioncom.orgzly.intent.action.SYNC_STARTfor Packagecom.orgzlyClasscom.orgzly.android.sync.SyncServiceTargetService. ↩︎ -
I am super slow working towards this, so if you want to offer up some elisp for me to use I would be most grateful. ↩︎